Keeping Track of Brand Mentions using n8n and Serper API

One thing that marketers often want to track is brand mentions. This can include mentions on social media platforms, like in a Reddit thread, or in blog posts written about the brand. The most common and manual way to do this is to go to Google, search for your brand name, and then use the advanced search tools to select a date range for the mentions you want to find. For instance, you can filter the results to show only the mentions from the past week.
However, if you need to keep track of multiple brands or several important keywords, this process can become tedious. That's why I've been looking for an automation solution. With n8n and the Serper API, this task becomes much easier.
n8n is a workflow automation tool similar to Zapier, but it offers more control. It allows you to create automated workflows that integrate with various tools and services. The Serper API provides Google search results through an API, enabling you to access the data anywhere you need.
To get started with the Serper API, first create an account and enter the keywords you're interested in, specifying that you want results only from the last week. Once you do this, you'll receive an API endpoint. You can then copy this endpoint and input it into n8n.
Setting up a workflow in n8n: The workflow is triggered on Monday morning. The first step involves making an HTTP API request to the endpoint provided by the Serper API. This request will return the Google search results in JSON format. We will then send this data to an LLM model, clean it up, and extract a simple list of relevant items. Finally, we will send this list of URLs to a Google Sheet.
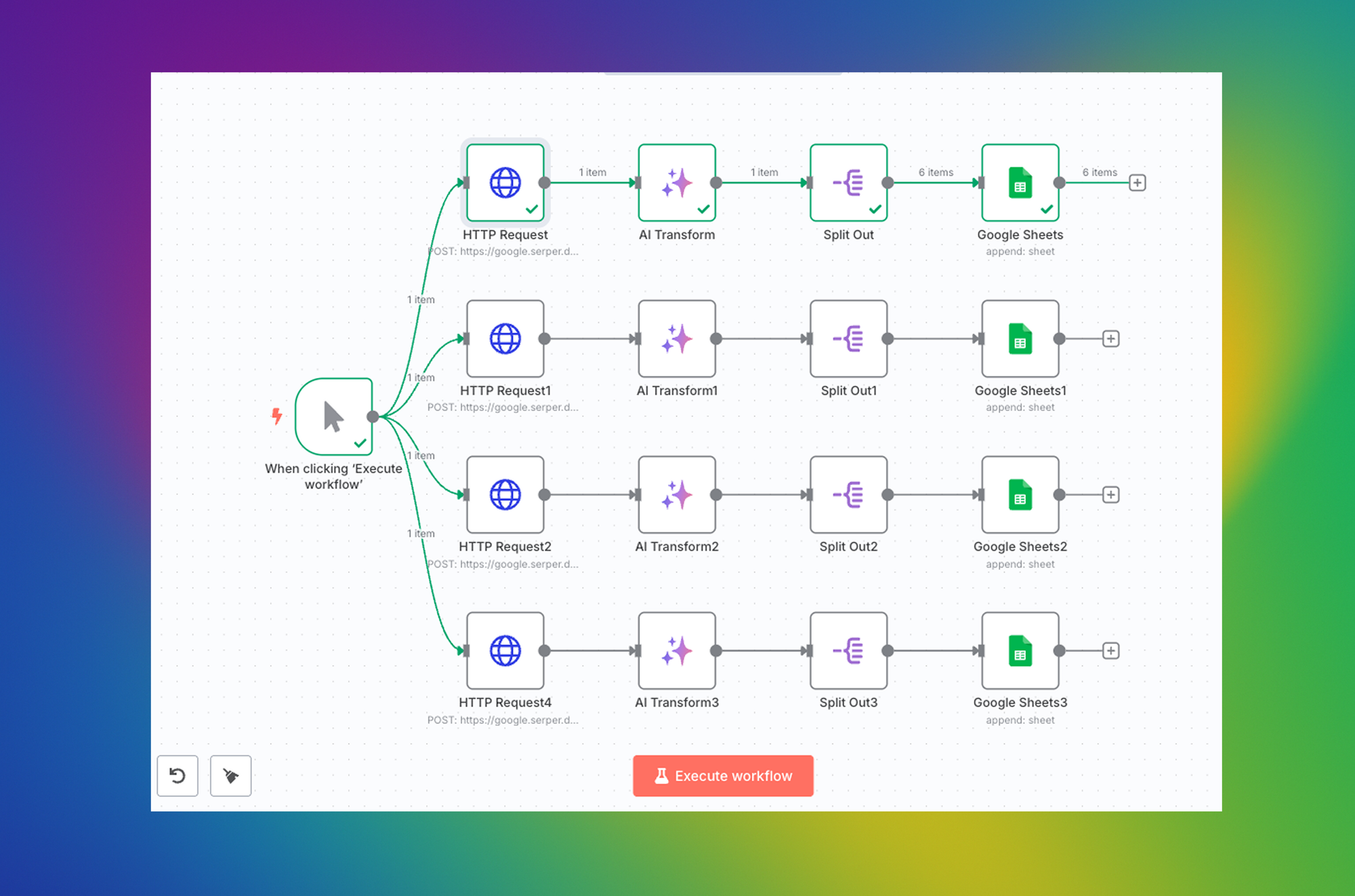
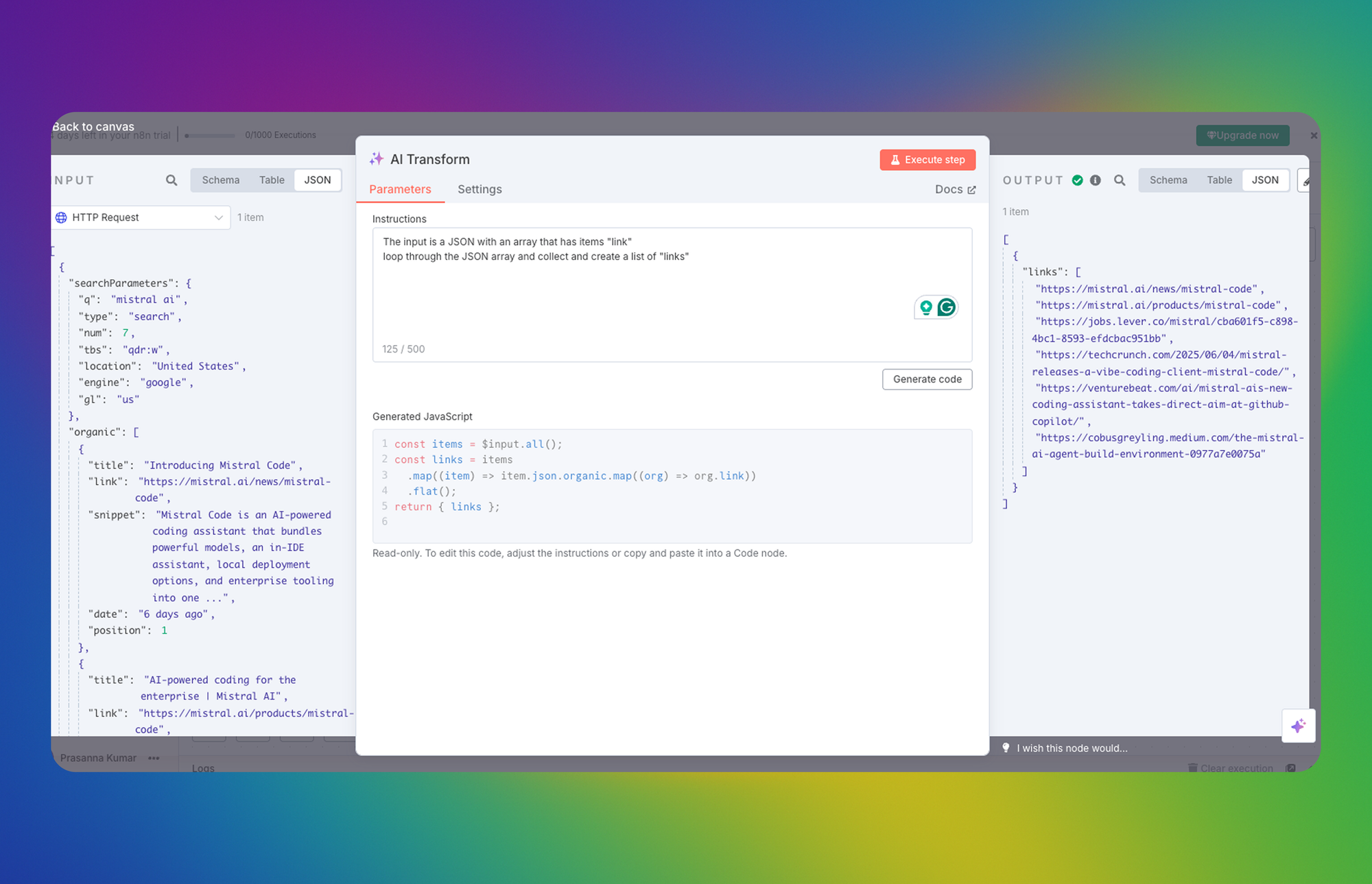
By running this workflow every Monday morning, you'll have a comprehensive overview of all the recent mentions related to your interests. That's how this integration works.
n8n is a fantastic no-code automation platform, but its pricing can be hard to justify when you’re a solo founder or running a micro-business. The hosted “Starter” plan begins at roughly €20/month, yet it caps you at only five concurrent executions—often too limiting for anything beyond the simplest workflows. The Pro plan lifts some restrictions, but at €50/month it quickly erodes a lean budget.
Yes, n8n is open-source, so in theory, you can self-host and avoid the SaaS fees. In practice, spinning up and maintaining a VPS (≈ $5/month), configuring Docker, securing the instance, and staying on top of updates introduce an overhead that many non-technical users would rather avoid.
My needs were straightforward: • Access a single REST API • Pull fresh data once a week • Append the results to a Google Sheet (or export them as CSV)
Instead of fighting pricing tiers or DevOps chores, I wrote a lightweight Python script that:
- Reads a list of URLs from a Google Sheet.
- Calls the server’s API for each URL.
- Writes the response data to a new CSV file.
Running the script once a week now takes seconds and costs me nothing. If your automation requirements are similarly modest, this minimal approach might save both money and hassle. Drop the code on your laptop, schedule a cron job, and you’re done—no subscriptions, no servers, no surprises.
Here is the Python code:
import requests
import json
import os
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
url = "https://google.serper.dev/search"
# Get API key from environment variable
api_key = os.getenv('SERPER_API_KEY')
if not api_key:
print("Error: SERPER_API_KEY not found in environment variables")
print("Please make sure you have a .env file with SERPER_API_KEY=your_api_key")
exit(1)
payload = json.dumps({
"q": "unstract",
"tbs": "qdr:w"
})
headers = {
"Content-Type": "application/json",
"X-API-KEY": api_key,
"Authorization": f"Bearer {api_key}" # Trying both formats as different APIs use different formats
}
try:
print("Sending request to Serper API...")
response = requests.post(url, headers=headers, data=payload)
# Print response details for debugging
print(f"Status Code: {response.status_code}")
print("Response Headers:", response.headers)
# Check if the request was successful
if response.status_code == 200:
print("\nSuccess! Here's the response:")
try:
print(json.dumps(response.json(), indent=2))
except json.JSONDecodeError:
print("Response is not in JSON format:")
print(response.text)
else:
print(f"\nError {response.status_code}:")
try:
print(json.dumps(response.json(), indent=2))
except json.JSONDecodeError:
print(response.text)
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
if hasattr(e, 'response') and e.response is not None:
print(f"Response status code: {e.response.status_code}")
print(f"Response text: {e.response.text}")
# the response is in json format so we can parse it there a item in the json response called "organic " that is a list of organic search results I want to extract only "link" from each item in the list
organic_results = response.json().get("organic", [])
for result in organic_results:
print(result.get("link"))
#from the above code get the extracted list of links and save it to a csv file in the same root folder
with open("links.csv", "w") as f:
for link in organic_results:
f.write(link.get("link") + "\n")The code can be found in Github